You have a website and would like to get a list of all pages on your site that are indexed in Google search. You would like to monitor the organic search rankings of your website for particular search keywords vis-a-vis other rival websites.
There are powerful command-line tools, curl and wget for example, that you can use to download Google search result pages. The HTML pages can then be parsed using Python’s Beautiful Soup library or the Simple HTML DOM parser of PHP but these methods are too technical and involve coding. The other issue is that Google is very likely to temporarily block your IP address should you send them a couple of automated scraping requests in quick succession.
Web Scraping Google using Google Docs
If you ever need to extract data from Google search results, Google offers a free tool that might just do the job. It’s called Google Docs and since it will be fetching Google search pages within Google’s own network, the scraping requests are less likely to get blocked.
The idea is simple. The Google Sheet will fetch and import Google search results using the built-in ImportXML function. It then extracts the page titles and URLs using XPath expressions and then grabs the favicons of the web domain using another Google’s own favicon converter.
To get started, open this Google sheet (or upgrade to Premium) and choose File -> Make a copy to clone the sheet in your Google Drive. Enter the search query in the yellow cell and it will instantly scrape the Google search result for that query.
And now that you have the Google Search results inside the sheet, you can export the data as a CSV file, publish the sheet as an HTML page (and it will refresh automatically) or you can go a step further and write a Google Script that will send you the sheet as PDF daily.
Advanced Google Scraping with Google Sheets
The idea is simple. The Google Sheet will fetch and import Google search results using the built-in ImportXML function. It then extracts the page titles and URLs using XPath expressions and then grabs the favicons of the web domain using another Google’s own favicon converter.
To get started, open this Google sheet (or upgrade to Premium) and choose File -> Make a copy to clone the sheet in your Google Drive. Enter the search query in the yellow cell and it will instantly scrape the Google search result for that query.
And now that you have the Google Search results inside the sheet, you can export the data as a CSV file, publish the sheet as an HTML page (and it will refresh automatically) or you can go a step further and write a Google Script that will send you the sheet as PDF daily.
Advanced Google Scraping with Google Sheets
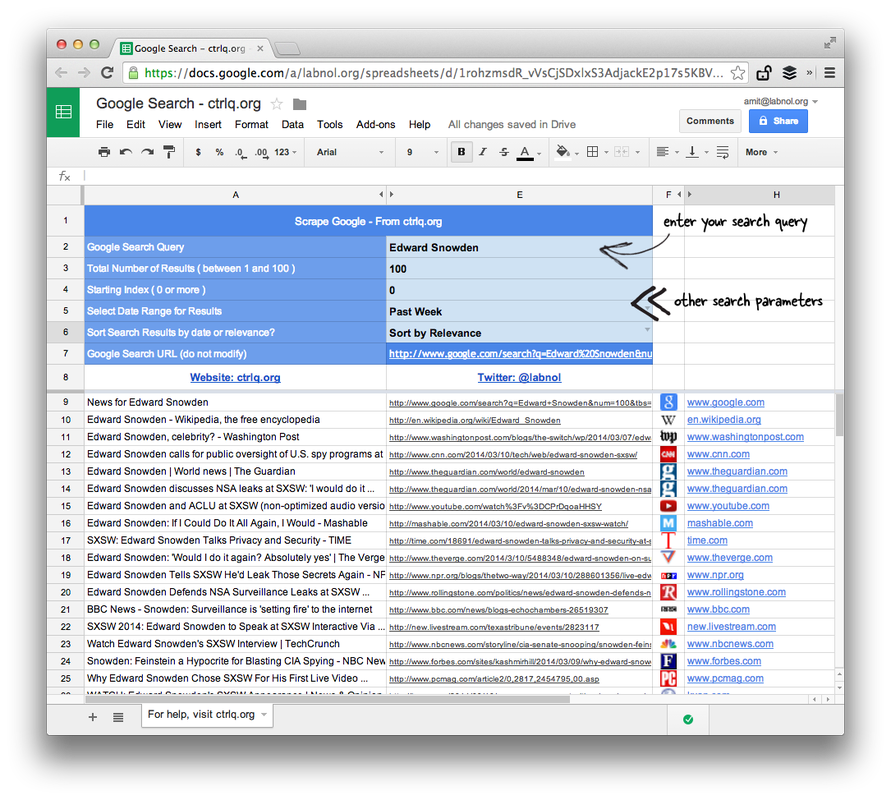
The premium edition of Google Scraper is more capable. It gives you the option to specify the number of search results you would like to fetch and the start index – handy if you wish to scrape not just the first page of Google.

The premium edition can fetch regular search results as well as local search results. You can also change the sorting criteria for search results – the results can be sorted by relevance or by date published. The search results can be restricted to pages that were published in the last hour, week, month or year. The number of results appearing in search results can be modified as well.
Spreadsheet Functions for Scraping Web Pages
Writing a scraping tool with Google sheets is simple and involve a few formulas and built-in functions. Here’s how it was done:
https://www.google.com/search?q=Edward+Snowden&num=10
=IMPORTXML(STEP1, "//h3[@'r']")
Spreadsheet Functions for Scraping Web Pages
Writing a scraping tool with Google sheets is simple and involve a few formulas and built-in functions. Here’s how it was done:
- Construct the Google Search URL with the search query and sorting parameters. You can also use advanced Google search operators like site, inurl, around and others.
https://www.google.com/search?q=Edward+Snowden&num=10
- Get the title of pages in search results using the XPath //h3 (in Google search results, all titles are served inside the H3 tag).
=IMPORTXML(STEP1, "//h3[@'r']")
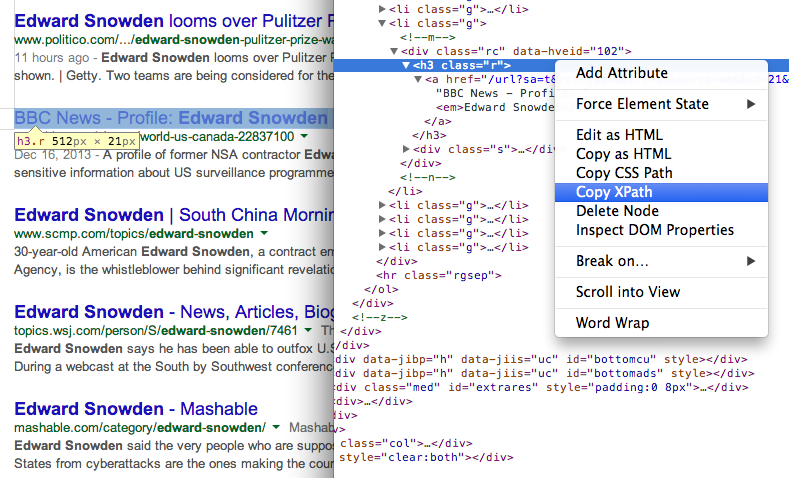
Find the XPath of any element using Chrome Dev Tools
=IMPORTXML(STEP1, "//h3/a/@href")
=REGEXEXTRACT(STEP3, "\/url\?q=(.+)&sa")
=REGEXEXTRACT(STEP4, "https?:\/\/(.[^\/]+)")
=IMAGE(CONCAT("http://www.google.com/s2/favicons?domain=", STEP5), 4, 16, 16)
- Get the URL of pages in search results using another XPath expression
=IMPORTXML(STEP1, "//h3/a/@href")
- All external URLs in Google Search results have tracking enabled and we’ll use Regular Expression to extract clean URLs.
=REGEXEXTRACT(STEP3, "\/url\?q=(.+)&sa")
- Now that we have the page URL, we can again use Regular Expression to extract the website domain from the URL.
=REGEXEXTRACT(STEP4, "https?:\/\/(.[^\/]+)")
- And finally, we can use this website with Google’s S2 Favicon converter to show the favicon image of the website in the sheet. The 2nd parameter is set to 4 since we want the favicon images to fit in 16×16 pixels.
=IMAGE(CONCAT("http://www.google.com/s2/favicons?domain=", STEP5), 4, 16, 16)

